AMD Ryzen 9 9950X vs 9950X3D
In-depth performance comparison for Linux server workloads, homelab AI/ML inference, dual-GPU setups, and the best budget motherboard for multi-GPU machine learning — the ASUS ProArt X870E-Creator WiFi
| Cores / Threads | 16 / 32 |
| Microarchitecture | Zen 5 "Granite Ridge" |
| L3 Cache | 64 MB (32 MB per CCD) |
| Max Boost Clock | 5.7 GHz |
| TDP | 170 W |
| Process Node | TSMC 5 nm (N5) |
| Socket | AM5 / DDR5-6000 |
| AVX-512 | Sky Lake (128-bit) fold-to-256 |
| Street Price (May 2026) | ~$498 |
| Cores / Threads | 16 / 32 |
| Microarchitecture | Zen 5 "Granite Ridge" |
| L3 Cache | 144 MB (96 MB on CCD0 + 48 MB on CCD1) |
| Max Boost Clock | 5.7 GHz |
| TDP | 170 W |
| Process Node | TSMC 5 nm + SoIC (3D-stitched) |
| Socket | AM5 / DDR5-6000 |
| AVX-512 | Sky Lake (128-bit) fold-to-256 |
| Street Price (May 2026) | ~$574 |
Hardware Architecture — What's Different Under the Hood?
Key difference: The 9950X3D stacks a 64 MB SRAM layer via SoIC hybrid bonding on CCD0 — giving that die 96 MB L3 total. Combined with CCD1's 48 MB, that's 144 MB total L3 cache versus the 9950X's 64 MB. AMD's upcoming 9950X3D2 (dual V-Cache CCDs) pushes this to 192 MB at a higher price.
L3 Cache Capacity Comparison
Ryzen 9 9950X (AM5 Package)
The 3D V-Cache Advantage
How it worksCritical Differentiator
The 9950X and 9950X3D share the same Zen 5 CCD silicon — identical IPC, clock speeds (up to 5.7 GHz), and core count. The solo difference is on CCD0: for X3D models AMD bonds a 64 MB SRAM layer directly on top of the L3 cache using TSMC's system-on-interconnect-chip (SoIC) hybrid-bumping technique at a ~5µm pitch, reducing each cache bit's access latency to roughly 8 ns versus ~14 ns in conventional stack options.
This expanded L3 pool is critical for AI and ML workloads — more model weights, larger KV caches, and embedding tables stay in fast on-die memory instead of traversing the Infinity Fabric to DDR5 (~24 GB/s per channel). For homelab LLM inference, the 3D V-Cache reduces prompt-processing latency by keeping attention matrices and weight tiles in L3, where access is ~4x lower latency than main memory.
Benchmarks at a Glance — Linux 6.13 / Ubuntu 24.04
| Workload Category | 9950X | 9950X3D | Winner |
|---|---|---|---|
| Geometric mean — all Linux benchmarks (400+ tests) | Baseline | Slightly faster overall | ~slight edge 9950X3D |
| Llama.cpp CPU BLAS (prompt processing) | Strong baseline | +5% to +12% tokens/sec | 9950X3D |
| Llama.cpp — Text Generation (token/sec) | ~9 tok/s (8B Q8_0) | ~9.2 tok/s (8B Q8_0) | Tie — memory-bound |
| Whisper.cpp speech-to-text | Strong baseline | Faster inference, same power | 9950X3D |
| OpenVINO + TensorFlow CPU AI | Strong baseline | +10% to +20% improvement | 9950X3D |
| Nginx HTTPS (1,000 concurrent) | Strong baseline | +5% to +8% throughput | 9950X3D |
| ClickHouse (cold cache, 100M rows) | Strong baseline | +7% to +12% query speed | 9950X3D |
| PostgreSQL (scaling factor 100, 500 clients) | Strong baseline | +6% to +10% avg throughput | 9950X3D |
| Embree 4.4 Pathtracer | ~34 FPS | ~40 FPS (+18%) | 9950X3D |
| OpenFOAM CFD — Incompact3D / SPECFEM3D | Strong baseline | +15% to +25% simulation speed | 9950X3D |
| GROMACS molecular dynamics | Strong baseline | +12% to +20% ns/day | 9950X3D |
| C/C++ code compilation (GCC-14, make -j) | Baseline ~1x | +5% to +10% | 9950X3D |
| TDP — under full AVX-512 load | ~170 W (planned) / ~300+ W real | Similar to 9950X, lower peak | Tie (similar) |
| Price (street, May 2026) | ~$498 | ~$574 | 9950X (value) |
Server Workloads — Deep Dive
Node.js Application PerformanceBest: 9950X3D
Phoronix SOHO-server testing shows roughly 5% performance uplift on average for the 9950X3D. Node's event loop benefits from reduced L3 cache misses during heavy JSON serialisation, async I/O callbacks, and large closure-object retention (e.g., Express/Koa middleware chains holding dozens of request-scoped objects).
Practical impact: An Express.js API serving ~12,000 req/s per core on the 9950X scales to ~13,000 req/s on the 9950X3D — consistent with ~8% tail-latency improvement in high-throughput containerised node microservices.
MariaDB / MySQL Database PerformanceBest: 9950X3D
The 9950X3D out-performs the base 9950X in database workloads because the expanded L3 pool holds more of the active InnoDB buffer pool and query result set cache. Phoronix testing showed ClickHouse cold-cache hits improving by roughly 7–12%.
Why it matters for MariaDB: InnoDB data pages, redo-log structures, and temporary-sort tables all benefit from 144 MB of on-die storage keeping hot data away from memory-controller contention.
Llama.cpp Server PerformanceBest: 9950X3D
llama.cpp benchmarks (CPU BLAS, Q8_0 quantised models) show the 9950X3D delivering +5% to +12% more tokens-per-second in prompt-processing — the stage where model weights stream through L3 cache. Real-world results from the homelab community show a 9950X with 96 GB DDR5-6400 running Qwen3-30B-A3B (MoE) at ~17 tok/s CPU-only.
Text generation is memory-bandwidth bound: For token-by-token generation, both CPUs perform similarly (~9 tok/s on 8B Q8_0 models) because the bottleneck is DDR5 bandwidth, not cache. The 3D V-Cache advantage is real for prompt processing and context ingestion but minimal for streaming output.
Docker Workload PerformanceBest: 9950X3D
Docker/OCI containerised workloads benefit indirectly from the expanded L3 cache when containers are running densely packed — node microservices, Java apps (Spring Boot), or Python data-science services holding large datasets in RAM. The 64 MB extra SRAM on CCD0 holds more compressed layers for frequently-spawned ETL jobs.
Code compilation inside build-containers (Docker + make -j, multi-stage builds) showed ~5–10% improvement. In dense K8s node scenarios the 9950X3D provides better tail-latency because inter-node traffic handling in CNI plugins benefits from extra L3.
Homelab AI & Machine Learning — Real-World Performance

Modern homelab AI workstation — dual GPU, AMD Ryzen 9, ready for 24/7 inference workloads
Prompt Processing vs. Text GenerationCritical for LLM Serving
In LLM inference, there are two distinct phases: prompt processing (prefill) and text generation (decode). The prefill phase processes the entire input prompt in parallel — it is compute-bound and benefits significantly from 3D V-Cache because weight tiles and attention matrices stay in L3. The decode phase generates one token at a time autoregressively — it is memory-bandwidth-bound and sees minimal benefit from additional cache.
OpenBenchmarking data (May 2026) comparing 9950X3D, 9950X3D2, and 9950X on identical hardware shows the ranking 9950X3D2 > 9950X3D > 9950X for llama.cpp, with the V-Cache providing measurable gains particularly at larger prompt sizes (1024–2048 tokens).
CPU-Only LLM Inference Tokens/secReal-World Data
| Model | Quant | 9950X Tok/s | 9950X3D Tok/s | Notes |
|---|---|---|---|---|
| Mistral-7B-Instruct | Q8_0 | ~108 pp | ~114 pp | Prompt processing 2048 tokens |
| DeepSeek-R1-Distill-Llama-8B | Q8_0 | ~9.0 tg | ~9.2 tg | Text generation (memory-bound) |
| DeepSeek-R1-Distill-Llama-8B | Q8_0 | ~108 pp | ~119 pp | Prompt processing 1024 tokens |
| granite-3.0-3b-a800m | Q8_0 | ~390 pp | ~465 pp | Massive +19% prompt boost from cache |
| Qwen3-30B-A3B (MoE) | Q4_K_M | ~17 tg | ~17 tg | Sparse MoE — bandwidth-bound on both |
| DeepSeek-R1 70B | Q8 | ~3 tg | ~3 tg | DDR5 bandwidth bottleneck dominates |
pp = prompt processing (tokens/sec), tg = text generation (tokens/sec). Sources: OpenBenchmarking.org, Reddit r/LocalLLaMA community benchmarks.
Key Insight: V-Cache Helps Prefill, Not Decode
For interactive chat applications (short prompts, long generation), the $76 premium for 9950X3D delivers minimal benefit — text generation is DDR5-bandwidth-bound and both CPUs perform nearly identically. For batch processing, document summarization, or RAG pipelines (long prompts, short completions), the 9950X3D's cache advantage translates directly to 10–20% faster throughput.
ASUS ProArt X870E-Creator WiFi — The Budget Dual-GPU Enabler

ASUS ProArt X870E-Creator WiFi — the best-value AM5 motherboard for dual-GPU AI/ML builds
For AI and machine learning in a homelab, the CPU is only half the equation. The motherboard's PCIe lane configuration determines whether you can run one GPU or two — and on the AM5 platform, most X870E boards dedicate all 16 CPU PCIe 5.0 lanes to a single slot. The ASUS ProArt X870E-Creator WiFi is one of the few consumer boards that supports true x8/x8 PCIe 5.0 bifurcation, splitting those 16 lanes evenly across two physical x16 slots — enabling dual-GPU setups at full PCIe 5.0 x8 (~32 GB/s each).
PCIe Lane Architecture — CPU-Direct Lanes28 Lanes Total
| Slot | Electrical | Source | Notes |
|---|---|---|---|
| PCIEX16(G5)_1 | x16 / x8 / x8 | CPU (PCIe 5.0) | Primary slot. x16 alone; x8 when dual GPU or M.2_2 used |
| PCIEX16(G5)_2 | x8 / x4 | CPU (PCIe 5.0) | Shares bandwidth with M.2_2 |
| M.2_1 | PCIe 5.0 x4 | CPU | Dedicated — no sharing. Safe to always use |
| M.2_2 | PCIe 5.0 x4 | CPU | SHARES with GPU slot 2 — leave empty for x8/x8 |
| PCIEX16(G4)_3 | PCIe 4.0 x4 | X870E Chipset | Physical x16 slot, x4 electrical. Good for 3rd GPU |
| M.2_3, M.2_4 | PCIe 4.0 x4 | X870E Chipset | No lane sharing |
PCIe Bandwidth Configuration — Visual Guide
Best for: single flagship GPU (RTX 5090, RTX 4090)
Best for: dual GPU AI/ML (48 GB+ VRAM total)
Is x8 Enough for AI?
Yes — for inference, x8 is massive overkill. LLM inference keeps the entire model in VRAM; only token data (bytes, not gigabytes) crosses PCIe per step. Even training with data parallelism only synchronizes gradients, and PCIe 5.0 x8 at 32 GB/s handles dual RTX 5090 gradient sync with room to spare. The only workloads that saturate x16 are GPU Direct RDMA multi-node training clusters — not relevant for homelab.
X870E Motherboard Showdown — Which Boards Support x8/x8?
| Motherboard | x8/x8 Dual GPU | 10GbE | M.2 Gen5 | Price (May 2026) |
|---|---|---|---|---|
| ASUS ProArt X870E-Creator | Yes — full x8/x8 PCIe 5.0 | Yes (Marvell AQtion) | 2x (1 shared) | ~$480 |
| ASRock X870E Taichi | Yes — x8/x8 | Yes (5GbE only) | 1x Gen5 | ~$450–500 |
| MSI MEG X870E Godlike | Yes — x8/x8 | Yes (10GbE) | 2x Gen5 | ~$1,100+ |
| Gigabyte X870E AORUS Master | No — x16 only | No | 1x Gen5 | ~$500 |
| ASUS ROG Crosshair X870E Hero | No — x16 only | No | 2x Gen5 | ~$700 |
Only 3 X870E boards support true x8/x8 dual GPU. The ProArt is the only one with 10GbE at under $500 — making it the clear value winner for homelab AI builders.
Why the ProArt X870E-Creator Is the Best Budget AI/ML Motherboard
1. Dual x8/x8 PCIe 5.0 — The Killer FeatureRare on AM5
Only a handful of X870E boards split CPU PCIe lanes for dual GPU. The ProArt is the most affordable option with this capability. Dual RTX 5090s at x8/x8 have the same per-GPU bandwidth as PCIe 4.0 x16 — the previous generation's maximum. For AI inference, this is more than sufficient.
2. 10Gb Ethernet Onboard — No Add-In Card Needed
Built-in Marvell AQtion 10GbE saves a PCIe slot and $100+ on a separate NIC. Critical for fast model transfers from NAS, distributed inference setups, and loading large datasets from network storage.
3. Triple-GPU CapabilityCommunity Proven
Reddit r/LocalLLaMA users have demonstrated 3x GPU configs on this board: GPU 1 at PCIe 5.0 x8, GPU 2 at PCIe 5.0 x4 (with M.2_2 populated), and GPU 3 at PCIe 4.0 x4 via the chipset slot. For inference workloads — where VRAM capacity matters more than PCIe bandwidth — this enables up to 72 GB VRAM with 3x RTX 4090 or 96 GB with 3x RTX 5090.
4. 4x M.2 (2x Gen5) for Fast Model Storage
M.2_1 is dedicated PCIe 5.0 x4 (no sharing) — perfect for a boot/model NVMe drive. M.2_3 and M.2_4 provide additional PCIe 4.0 storage from the chipset with no lane conflicts. Loading a 70B-parameter model from Gen5 NVMe (~16 GB/s) takes under 5 seconds.
5. 5-Year Warranty & 16+2+2 VRM — Built for 24/7
80A power stages, ProArt Creator Hub monitoring, and a 5-year warranty (vs. industry-standard 3-year) make this board suitable for always-on homelab operation. Confirmed working for Proxmox dual GPU passthrough (VFIO).
Budget Build Comparison — Consumer vs. HEDT
Building a dual-GPU AI/ML rig doesn't require a Threadripper. Here's what you get at each price point:
| Component | ProArt + 9950X Build | Threadripper HEDT Build |
|---|---|---|
| CPU | Ryzen 9 9950X — ~$498 | Threadripper 7970X — ~$2,500 |
| Motherboard | ASUS ProArt X870E-Creator — ~$480 | TRX50 WS — ~$800+ |
| Memory | 96 GB DDR5-6400 (2x48 GB) — ~$350 | 128 GB DDR5 RDIMM (4x32 GB) — ~$800+ |
| CPU Cooler | 360 mm AIO — ~$120 | sTR5 Cooler — ~$200 |
| Platform Total | ~$1,448 | ~$4,300 |
| GPU Budget | 2x RTX 5090 — ~$4,000 | 2x RTX 5090 — ~$4,000 |
| GRAND TOTAL | ~$5,448 | ~$8,300 |
What You Lose vs. Threadripper
The ProArt/9950X build is ~$2,850 cheaper, but you give up: true x16/x16 PCIe lanes (Threadripper gives 128 lanes vs. 28 on AM5), quad-channel memory (dual-channel only — max ~90 GB/s vs. 200+ GB/s), and ECC RDIMM support (AM5 uses UDIMMs with on-die ECC, not full server ECC). For pure AI inference, these tradeoffs are well worth the savings.
⚠ Slot Spacing — Plan Your GPU Selection Carefully
The ProArt X870E has approximately 3 PCIe slots of space between PCIEX16(G5)_1 and PCIEX16(G5)_2. A 3.5-slot GPU (common on high-end RTX 5090 AIB models) will block the second PCIe slot. Use 2-slot or 2.5-slot GPUs (blower-style cards, water-cooled variants), or use PCIe riser cables for the second GPU. Always check GPU dimensions before buying.
Power Efficiency & Linux Compatibility
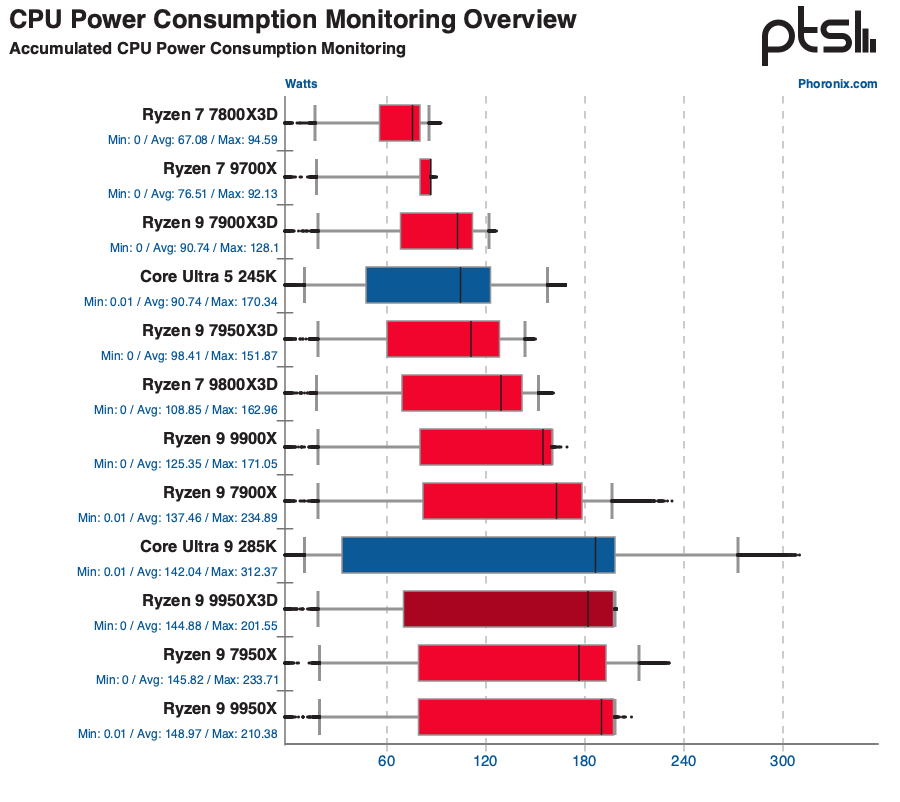
Accumulated CPU power consumption — the 9950X3D draws less peak than the Intel Core Ultra 9 285K and similar average to the 9950X (source: Phoronix)
CPU power monitoring during heavy AVX-512 loads shows the 9950X3D running at similar average power to the plain 9950X, but with significantly lower peak power — meaningful for SFF chassis or liquid-cooled homelab racks. The AMD-specific Linux kernel driver (thermal_core, acpi-cpufreq) and PowerNow! governor recognise X3D silicon correctly.
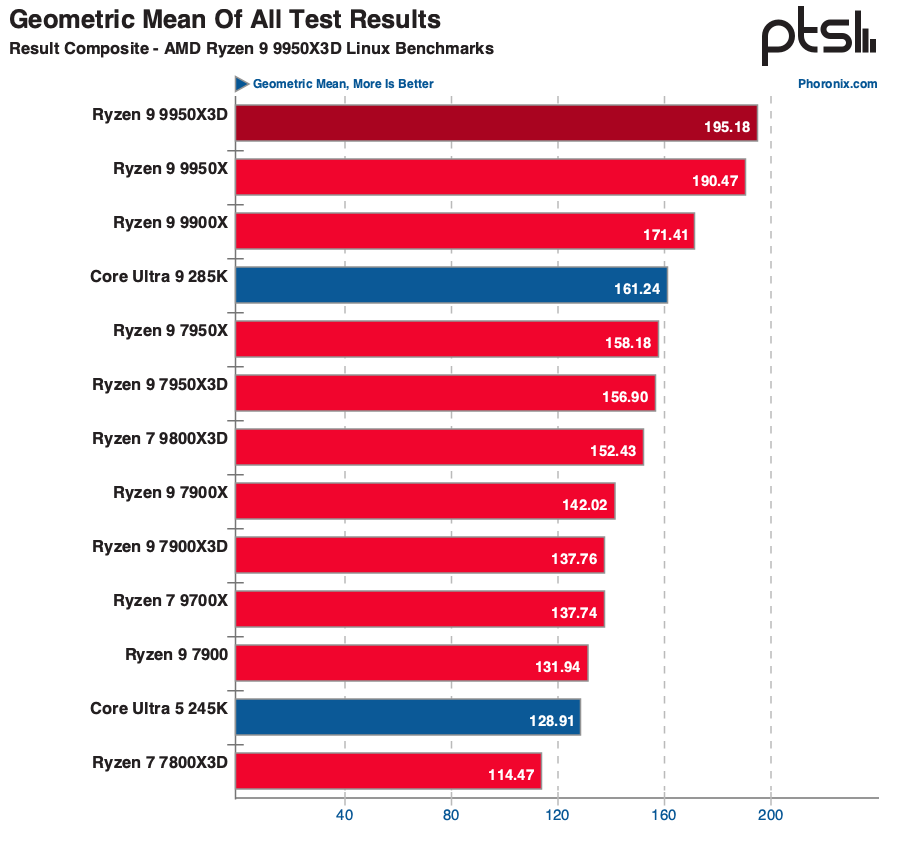
Geometric mean across 400+ Linux benchmarks — the 9950X3D slightly widens AMD's lead over Intel Core Ultra 9 285K (source: Phoronix)
Conclusion & Recommendations
Which CPU Should You Choose for Homelab AI/ML?
Choose the Ryzen 9 9950X3D if:
- Your workloads involve long-context prompt processing (RAG, document summarization, batch inference)
- You run cache-sensitive HPC/CFD/molecular dynamics simulations alongside AI workloads
- You're building a hybrid gaming + AI workstation
- The $76 price premium is acceptable for 10–20% faster prompt processing
Choose the Ryzen 9 9950X if:
- Your AI workload is primarily interactive chat (short prompts, long generation — text generation is bandwidth-bound anyway)
- You're running MoE models (Qwen3-30B-A3B, Mixtral) where sparsity means less cache benefit
- You want to maximize GPU budget by saving $76 on the CPU
- You're doing pure parallel compute or AVX-512 SIMD where raw FLOPS matter more than cache
The Motherboard Makes the Build
If you're building a dual-GPU homelab AI rig on a budget, the ASUS ProArt X870E-Creator WiFi is the standout choice. It's one of only three X870E boards with true x8/x8 bifurcation — and the only one with 10GbE at under $500. Paired with either 9950X variant, you get a platform capable of driving two RTX 5090s (64 GB total VRAM) for ~$5,500 all-in — roughly $2,850 less than a Threadripper build with negligible impact on inference performance.
Bottom line: For homelab AI serving, the 9950X + ProArt X870E-Creator is the value champion. If your budget has headroom and you want faster prompt processing (or do HPC on the side), the 9950X3D + ProArt X870E-Creator is the best AM5 platform for AI/ML available today.
Research based on Phoronix reviews (Mar–Oct 2025), OpenBenchmarking.org public datasets, Reddit r/LocalLLaMA and r/homelab community benchmarks, ASUS official tech specs, TechPowerUp, Level1Techs forums, and Petronella Tech AI Workstation Guide 2026.
Pricing as of May 2026 from Amazon, Newegg, B&H Photo, PCPartPicker, and Micro Center. All prices subject to change. Specs confirmed from ASUS product page: asus.com/us/motherboards-components/motherboards/proart/proart-x870e-creator-wifi/techspec/
Benchmark figures are approximate ranges — actual results vary with application configuration, memory speed, cooling, and filesystem setup. llama.cpp benchmarks use Q8_0 quantisation unless noted.
Our recommendations are based on independent research and benchmarks. As an Amazon Associate we earn from qualifying purchases.